Der Regelbruch – das Problem mit Konzeptschriften
Release 1.10.1
Konzeptschriften werden verwendet, wenn ein Schreiber schnell einen Entwurf anfertigt, der erst später „ins Reine“ geschrieben wird. Bei den Spruchakten sind dies die später verschickten Urteile. Diese Schriften sind meist sehr flüchtig und „unordentlich“ geschrieben. Oftmals werden dabei Buchstaben ausgelassen oder Wortendungen „verschluckt“. Konzeptschriften sind schon für den menschlichen Leser oft nicht leicht zu entziffern. Für die HTR stellen sie eine besondere Herausforderung dar.
Um ein HTR-Modell für das Lesen von Konzeptschriften zu trainieren, geht man ganz ähnlich vor, wie beim Traininig eines Modells, das Abbreviaturen interpretieren soll. Das HTR-Modell muss in beiden Fällen befähigt werden, etwas zu lesen, was überhaupt nicht da ist – nämlich fehlende Buchstaben und Silben. Um das zu erreichen muss die Transkriptionsregel: „Wir transkribieren als Ground Truth nur das, was auch wirklich auf dem Papier steht“ gebrochen werden. Wir müssen vielmehr alle ausgelassenen Buchstaben und fehlende Wortendungen etc. in unsere Transkription einfügen. Anders werden wir am Ende kein sinnvolles und durchsuchbares HTR-Ergebnis erhalten.
Bei unseren Versuchen mit Konzeptschriften hatten wir zuerst versucht spezielle HTR-Modelle für Konzeptschriften zu trainieren. Der Erfolg damit war eher gering. Schließlich sind wir dazu übergegangen, Konzeptschriften – ähnlich wie die Abbreviaturen – direkt innerhalb unseres generischen Modells mit zu trainieren. Dabei haben wir immer wieder überprüft, ob der „falsche Ground Truth“ den wir dabei produzieren, das Gesamtergebnis unseres HTR-Modells verschlechtert. Überraschender weise hatte das Brechen der Transkriptionsregeln, keinen messbaren negativen Effekt auf die Qualität des Modells. Das ist wahrscheinlich auch auf die schiere Menge des Ground Truth zurückzuführen, der in unserem Fall verwendet wird (ca. 400.000 Wörter).
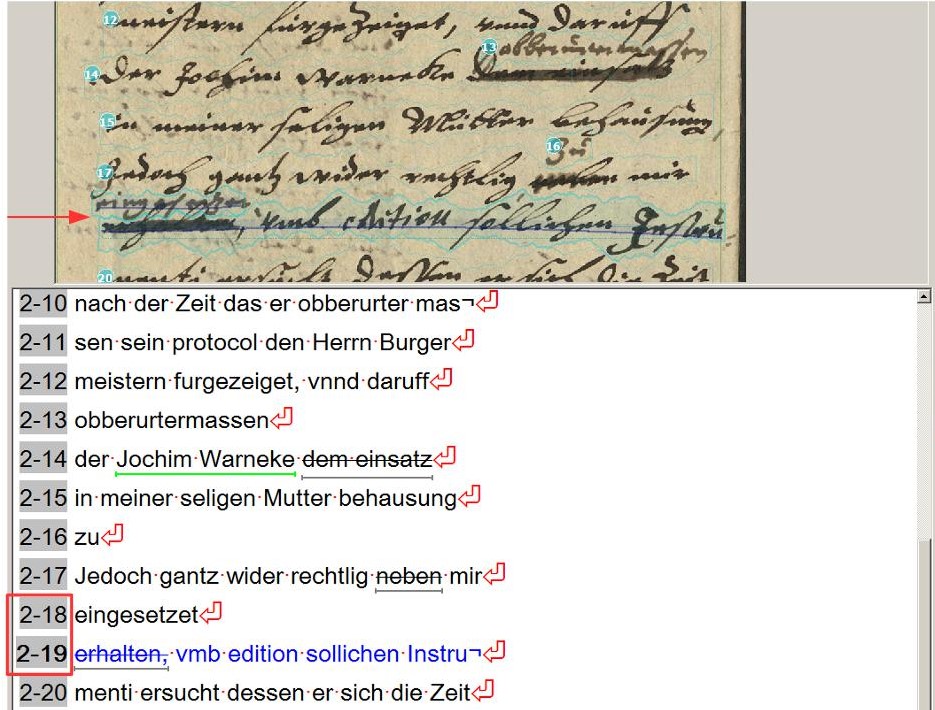
HTR-Modelle sind also in der Lage Konzeptschriften von Reinschriften zu unterscheiden und entsprechend zu interpretieren – innerhalb bestimmter Grenzen. Unten findet ihr einen Vergleich des HTR-Ergebnisses mit dem GT bei einer typischen Konzeptschrift aus unserem Material.