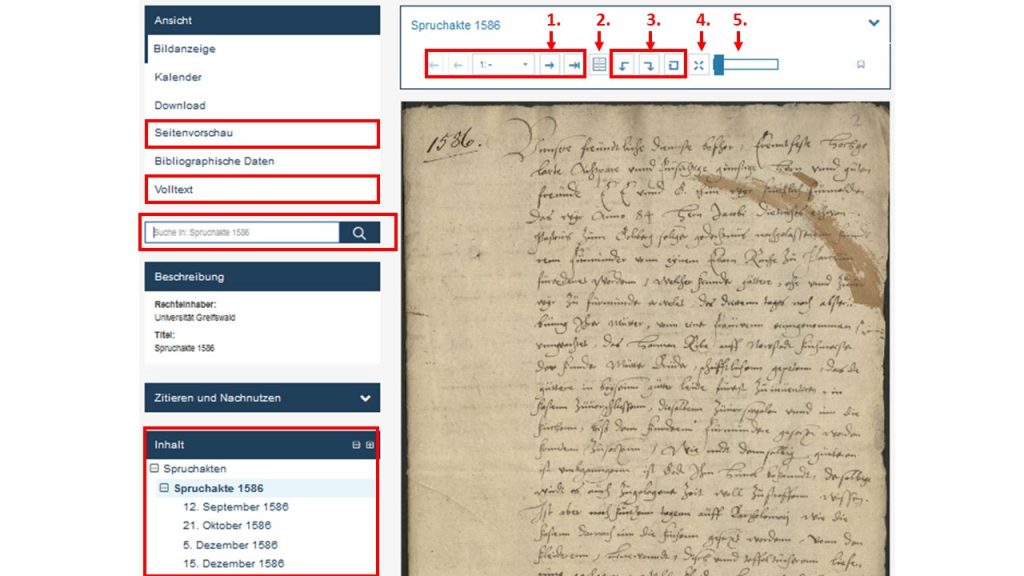
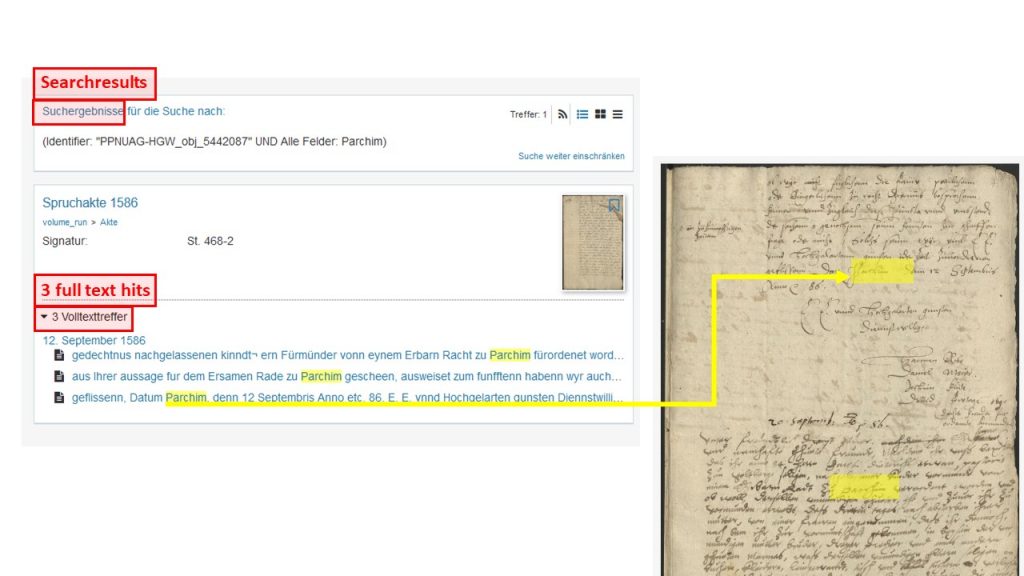
In den Abschriften für den Ground Truth wird die litterale oder diplomatische Transkription angestrebt. Das bedeutet, dass wir bei der Transkription möglichst keine Regulierungen hinsichtlich der Zeichen vornehmen. Die Maschine muss anhand einer möglichst zeichengetreuen Abschrift lernen, um selbst später genau wiedergeben zu können, was auf dem Blatt zu lesen ist. So übernehmen wir beispielsweise konsequent die vokalische und konsonantische Verwendung von „u“ und „v“ der Vorlage. An das Vrtheill vndt die Vniusersitet kann man sich erstaunlich rasch gewöhnen.
Nur in den folgenden Ausnahmen sind wir von der litteralen Transkription abgewichen und haben Zeichen reguliert. Auf die Behandlung von Abbreviaturen gehen wir noch einmal gesondert ein.
Das ſogennante Lang-s und das Schluß-s oder auch runde S können wir nicht litteral übernehmen, weil wir weitgehend auf das Antiqua-Zeichensystem angewiesen sind. Daher übertragen wir beide Formen als „s“.
Umlaute geben wir so wieder, wie sie erscheinen. Diakritische Zeichen werden übernommen, es sei denn das moderne Zeichensystem erlaubt dies nicht; wie im Fall des „a“ mit ‚diakritischem e‘, das zum „ä“ wird. Diphthonge werden ebenfalls übernommen, das „æ″ allerdings als „ae″.
Das Ypsilon wird in vielen Handschriften als „ÿ″ geschrieben. Wir transkribieren es aber in der Regel als einfaches „y″. Nur wenn es paläografisch begründet ist, differenzieren wir zwischen „y“ und dem ähnlich verwendeten „ij“.
Auch hinsichtlich der Satz- und Sonderzeichen gibt es einige Ausnahmen von der litteralen Transkription: In den Handschriften werden Klammern auf ganz unterschiedliche Weisen dargestellt. Wir verwenden hier aber einheitlich die modernen Klammerzeichen (…). Auch die Worttrennungszeichen am Zeilenende weisen eine hohe Varianz auf, weshalb wir sie ausschließlich mit einem „¬“ wiedergeben. Das im modernen Gebrauch übliche Kupplungszeichen – der Bindestrich – kommt in den Handschriften kaum vor. Stattdessen finden wir bei Kupplung zweier Wörter häufig das „=“, das wir mit einem einfachen Bindestrich wiedergeben.
Die Komma- und Punktsetzung übernehmen wir so wie sie erscheint – sofern überhaupt vorhanden. Endet der Satz nicht mit einem Punkt setzen wir auch keinen.
Groß- und Kleinschreibung wird unverändert nach der Vorlage übernommen. Häufig kann aber nicht eindeutig unterschieden werden ob es sich um einen Groß- oder Kleinbuchstaben handelt. Das betrifft weitgehend schreiberunabhängig insbesondere das D/d, das V/v und auch das Z/z. Im Zweifelsfall gleichen wir dann den fraglichen Buchstaben mit seiner sonstigen Verwendung im Text ab. In Komposita können Großbuchstaben innerhalb eines Wortes vorkommen – auch sie werden getreu nach der Vorlage transkribiert.