HTR+ oder Pylaia
Version 1.12.0
Wie ihr sicher schon gesehen habt, gibt es seit dem vergangenen Sommer neben HTR+ eine zweite Technologie für die Handschriftentexterkennung in Transkribus verfügbar – PyLaia.
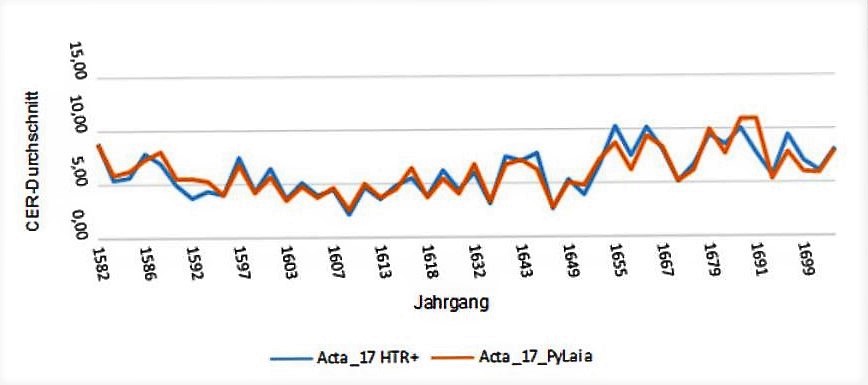
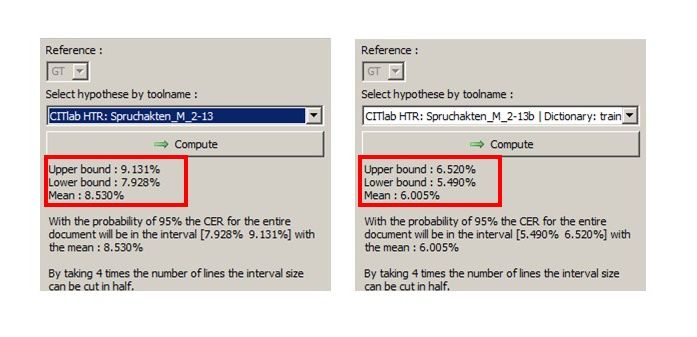
Wir haben in den vergangenen Wochen mit PyLaia-Modellen experimentiert und möchten hier einige erste Erfahrungen und Eindrücke zu den Unterschieden von HTR+ und PyLaia dokumentieren. Heißt billiger auch schlechter? – Definitiv nein! Hinsichtlich der Accuracy Rate kann PyLaia es ohne weiteres mit HTR+ aufnehmen. Es ist oft sogar etwas besser. Die folgende Grafik vergleicht ein HTR+ und ein PyLaia-Modell, die mit identischem Ground Truth (ca. 600.000 Wörter) unter denselben Voraussetzungen (from the scratch) trainiert wurden. Verglichen wird die Perfomance mit und ohne Language Model.
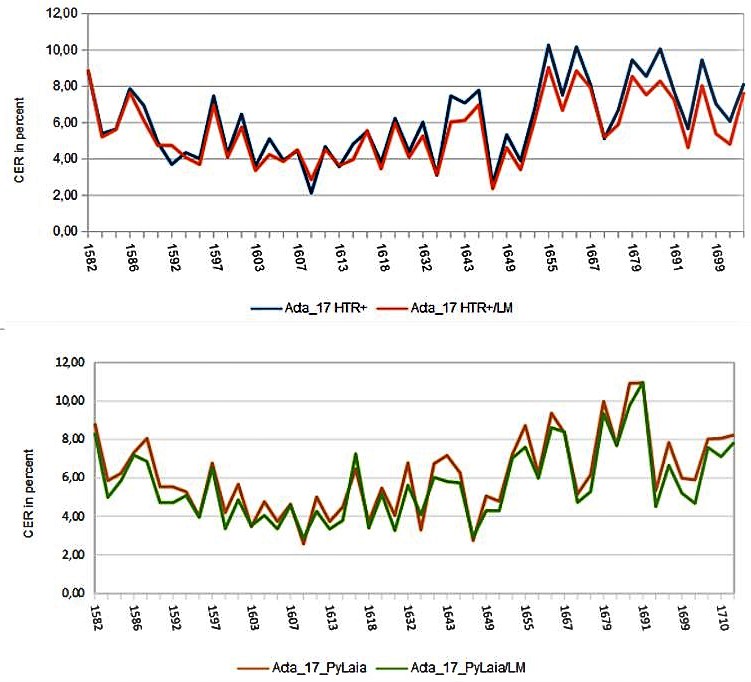
Der vielleicht auffälligste Unterschied ist, dass die Ergebnisse von PyLaia-Modellen sich mit dem Einsatz eines Language Models nicht ganz so stark verbessern lassen, wie das bei HTR+ der Fall ist. Das ist nicht unbedingt ein Nachteil, sondern spricht eigentlich eher für eine hohe Grundverlässlichkeit dieser Modelle. Anders ausgedrückt: PyLaia braucht nicht unbedingt ein Language Model um sehr gute Ergebnisse zu erzielen.
Es gibt auch ein Gebiet, auf dem PyLaia schlechter abschneidet, als HTR+. PyLaia hat größere Schwierigkeiten „gebogene“ Zeilen korrekt zu lesen. Bei senkrechten Textzeilen ist das Ergebnis sogar noch schlechter.
Im Training ist PyLaia etwas langsamer als HTR+, das heißt, das Training dauert länger. Auf der anderen Seite ist PyLaia sehr viel schneller im „Antritt“. Es benötigt verhältnismäßig wenige Trainingsdurchgänge, um gute Ergebnisse zu erzielen. In den beiden Lernkurven kann man das recht gut erkennen.
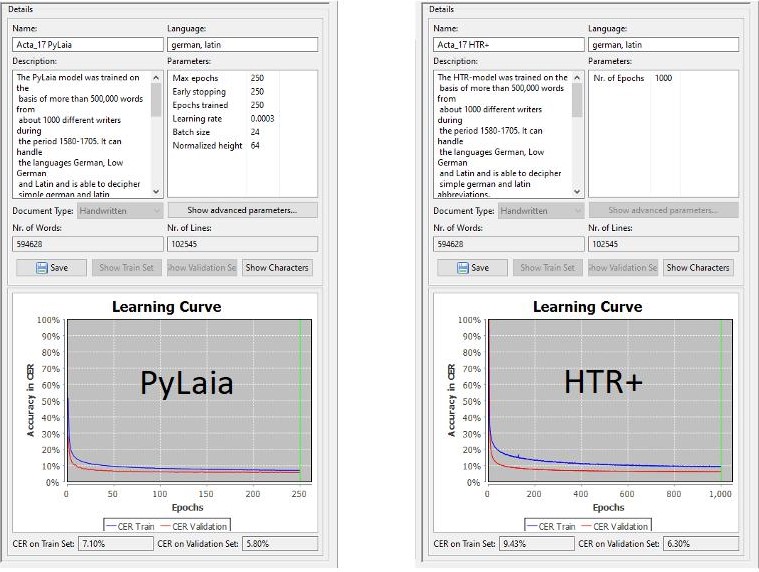
Unsere Beobachtungen sind natürlich nicht erschöpfend. Sie beziehen sich bisher nur auf generische Modelle, die mit einem hohen Einsatz von Ground Truth trainiert wurden. Wir haben insgesamt den Eindruck, das PyLaia bei solchen großen generischen Modellen seine Vorzüge voll ausspielen kann.