
Gesamtmodell oder Spezialmodell
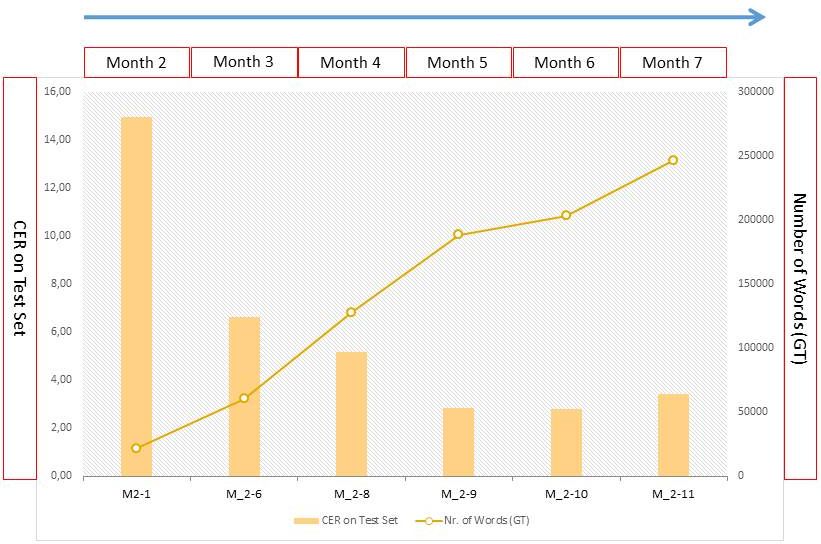
Ist dir in dem Diagramm zur Modellentwicklung aufgefallen, dass die Zeichenfehlerquote (CER) des letzten Modells wieder etwas schlechter wurde? Und das, obwohl wir den GT-Input deutlich gesteigert hatten? Wir hatten rund 43.000 mehr Wörter im Training aber eine Verschlechterung der durchschnittlichen CER von 2,79 auf 3,43 %. Erklären konnten wir uns das nicht so richtig.
{kind=link}
An dieser Stelle kamen wir mit immer mehr GT doch nicht so richtig weiter. Wir mussten also unsere Trainings-Strategie ändern. Bisher hatten wir Gesamtmodelle trainiert, mit Schriften aus einem Gesamtzeitraum von 70 Jahren und von über 500 Schreibern.
Unser erster Verdacht fiel auf die Konzeptschriften, von denen wir schon wussten, dass die Maschine (LA und HTR) – wie wir auch – damit ihre Probleme hat. Beim nächsten Training schlossen wir deshalb diese Konzeptschriften aus und trainierten also nur mit „sauberen“ Kanzleischriften. Eine auffällige Verbesserung brachte das aber nicht: die Test Set-CER sank von 3,43 auf gerade einmal 3,31 %.
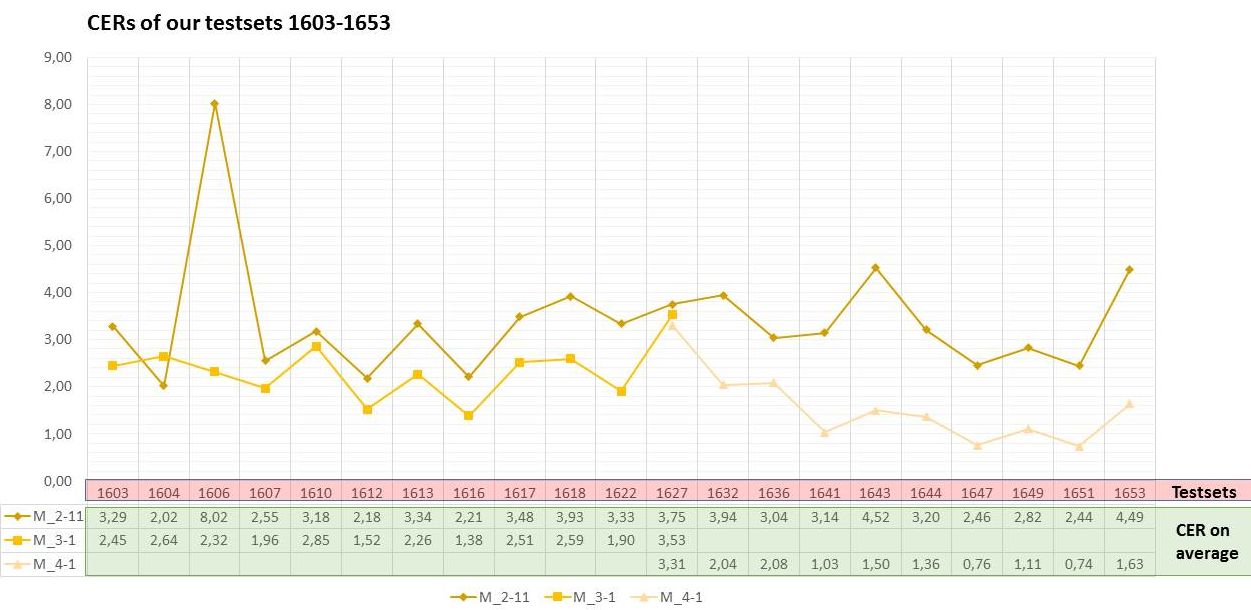
Im den darauf folgenden Trainings setzten wir dann zusätzlich auf eine chronologische Sequenzierung der Modelle. Wir teilten unser Material und erstellten zwei verschiedene Modelle: Spruchakten_M_3-1 (Spruchakten 1583-1627) und Spruchakten_M_4-1 (Spruchakten 1627-1653).
Mit den neuen Spezialmodellen erreichten wir tatsächlich wieder eine Verbesserung der HTR – wo das Gesamtmodell nicht mehr ausgereicht hatte. In den Testsets wiesen jetzt etliche Seiten eine Fehlerquote von unter 2 % auf. Im Fall des M_4-1er Modells blieben viele Seiten-CERs unter 1 % und zwei Seiten sogar fehlerfrei mit 0 %.
Ob ein Gesamt- oder Spezialmodell weiterhilft und die besseren Ergebnisse bringt, hängt natürlich sehr vom Umfang und der Zusammenstellung des Materials ab. Am Anfang, wenn du noch „Masse machen“ willst (viel hilft viel) lohnt sich ein Gesamtmodell. Wenn das aber an seine Grenzen kommt, solltest du die HTR nicht weiter „überfordern“ sondern stattdessen deine Modelle spezialisieren.