Anwendungsfall: „Modell Booster“
Release 1.10.1
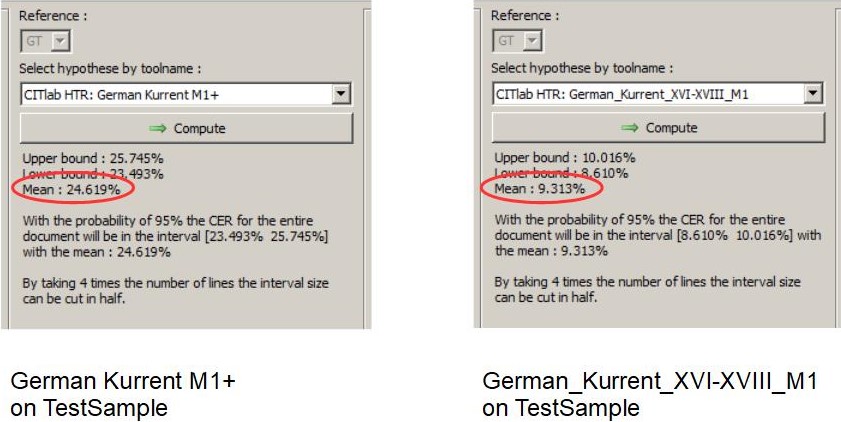
Unser Beispiel ist die Verbesserung unseres HTR-Modells für die Spruchakten. Das ist ein HTR-Modell, dass Kurrentschriften des 17. Jahrhunderts lesen kann. Auf der Suche nach einem möglichen Base Model findet man in den „public models“ von Transkribus zwei Kandidaten, die in Frage kommen: „German Kurrent M1+“ vom Transkribus Team und „German_Kurrent_XVI-XVIII_M1“ von Tobias Hodel. Beide könnten passen. Der Test auf dem Sample Compare ergibt allerdings, dass „German_Kurrent_XVI-XVIII_M1“ mit einer vorhergesagten mittleren CER von 9,3% auf unserem Sample Set die bessere Performance zeigte.
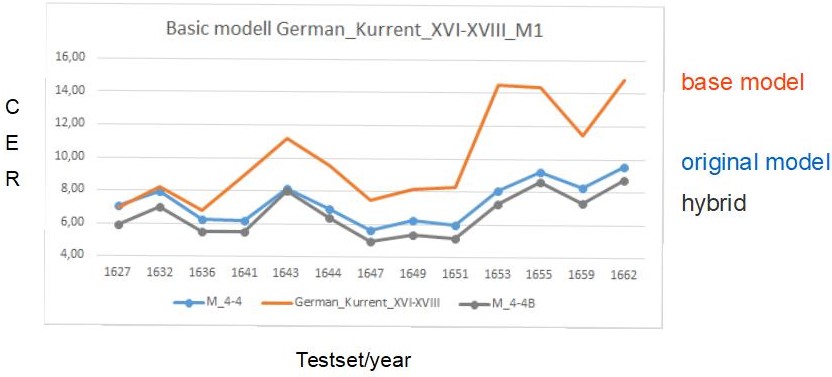
Für das Training wurde also „German_Kurrent_XVI-XVIII_M1“ als Base Model ausgewählt. Danach wurde der Ground Truth der Spruchakten (108.000 Wörter) und auch das Validation Set unseres alten Modells hinzugefügt. Die durchschnittliche CER unseres HTR-Modells hat sich nach dem Base Model Training erheblich verbessert, von 7,3% auf 6.6%. In der Grafik seht ihr, dass das Base Model auf dem Testset zwar wesentlich schlechter gelesen hat, als das Originalmodell, dass der Hybrid aus beiden aber besser ist als beide einzeln. Die Verbesserung des Modells ist in jedem einzelnen der getesteten Jahre zu beobachten und beträgt bis zu 1%.