„zwischen den Zeilen“ – Behandlung von Einfügungen
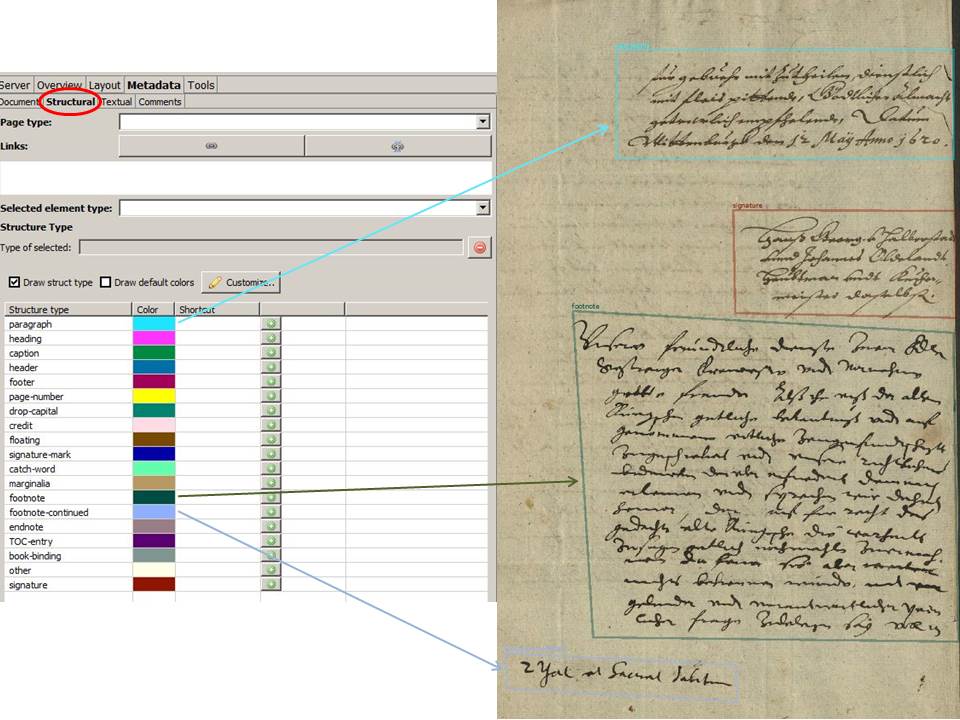
Mindestens genauso häufig wie Streichungen oder Schwärzungen kommen Überschreibungen oder zwischen die Zeilen geschriebene, eingefügte Textpassagen vor. Hier ist es in zweierlei Hinsicht nützlich, wenn man schon zu Anfang eines Projektes klärt, wie diese Fälle behandelt werden sollen.
In diesem einfachen Beispiel könnt Ihr sehen, wie wir solche Fälle handhaben.
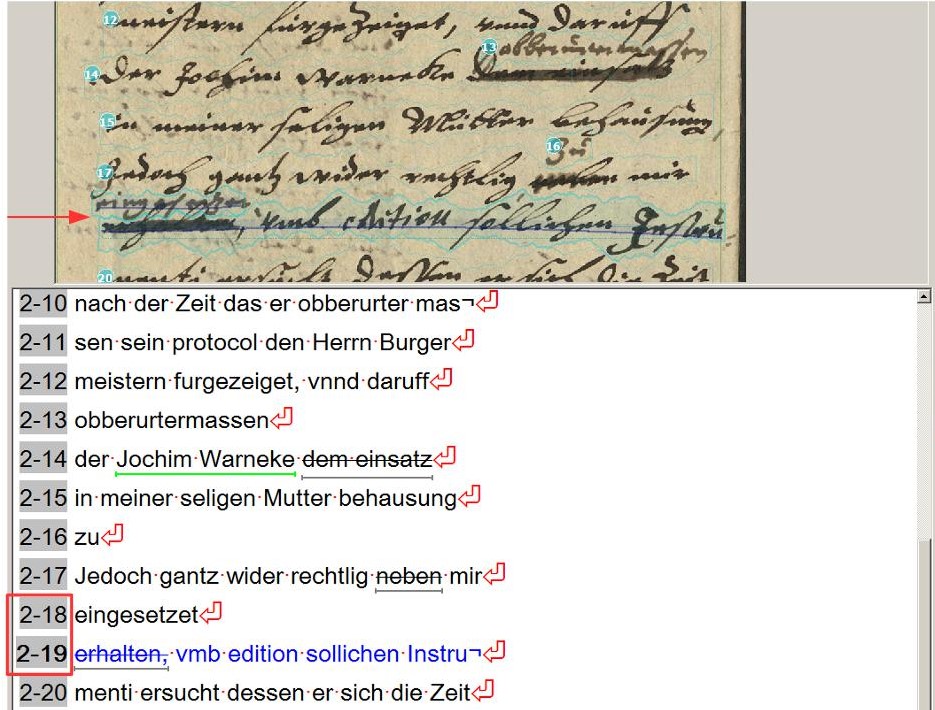
Da wir Streichungen und Schwärzungen sowohl im Layout als auch im Text erfassen, ist es nur konsequent, wenn wir die Überschreibungen und Einfügungen ebenso behandeln. Meist werden solche Passagen schon bei der automatischen Layoutanalyse mit separaten Baselines versehen. Hin und wieder muss man da korrigieren. Auf jeden Fall wird jede Einfügung von uns als eigene Zeile behandelt und auch in der Reading Order entsprechend berücksichtigt.
Auf keinen Fall sollte man das transkribiren was über der Streichung steht, da diese Überschreibungen oder Einfügungen eine eigene Baseline haben. Auf diese Weise würde das Trainingsmaterial versfälscht, auch wenn die Präsentation des Textes für das menschliche Auge natürlich gefälliger wäre.