Warum Testsets wichtig sind und wie man sie anlegt, #1
Release 1.7.1
Wenn wir überprüfen wollen, wieviel ein Modell im Training gelernt hat, müssen wir es auf die Probe stellen. Das tun wir mit Hilfe von möglichst genau definierten Testsets. Testsets enthalten – wie das Trainingsset – ausschließlich GT. Allerdings stellen wir sicher, dass dieser GT niemals für das Training des Modells verwendet wurde. Das Modell „kennt“ dieses Material also nicht. Das ist die wichtigste Eigenschaft von Testsets. Denn eine Textseite, die schon einmal als Trainingsmaterial diente, wird vom Modell immer besser gelesen werden, als eine, mit der es noch nicht „vertraut“ ist. Das kann man experimentell leicht überprüfen. Will man also valide Aussagen über die CER und WER erhalten, benötigt man „nicht korrumpierte“ Testsets.
Fast genauso wichtig ist, dass ein Testset repräsentativ ist. Solange man ein HTR-Modell für einen einzigen Schreiber oder eine individuelle Handschrift trainiert, ist das nicht schwer – es ist ja schließlich immer dieselbe Hand. Sobald mehrere Schreiber im Spiel sind, muss darauf geachtet werden, dass möglichst alle individuellen Handschriften die im Trainingsmaterial verwendet werden, auch im Testset enthalten sind. Je mehr unterschiedliche Handschriften in einem Modell trainiert werden desto größer werden die Testsets.
Der Umfang des Testsets ist ein weiterer Faktor, der die Repräsentativität beeinflusst. In der Regel sollte ein Testset 5-10% des Umfangs des Trainingsmaterials enthalten. Diese Faustregel sollte aber immer an die spezifischen Anforderungen des Materials und der Trainingsziele angepasst werden.
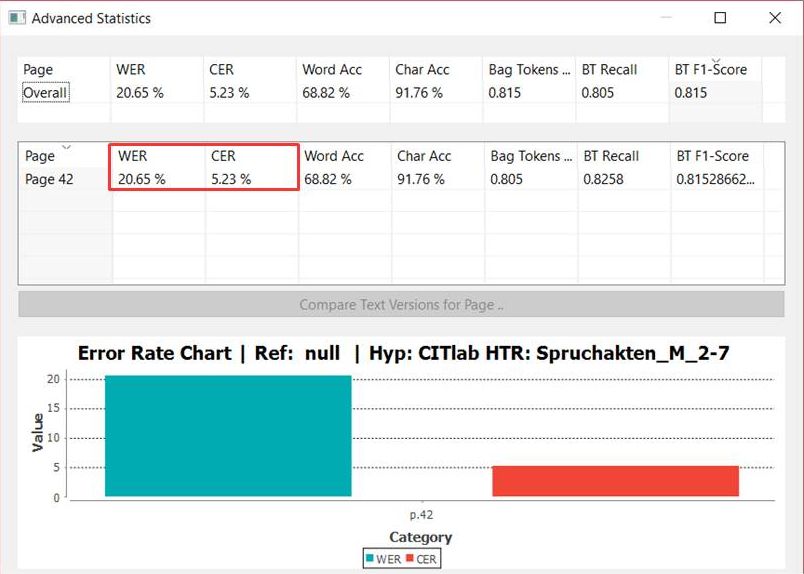
Um das einmal an zwei Beispielen zu erläutern: Unser Modell für die Spruchakten von 1580 bis 1627 wurde mit einem Trainingsset von fast 200.000 Wörtern trainiert. Das Testset beinhaltet 44.000 Wörter. Das ist natürlich ein sehr hoher Anteil von fast 20%. Er ist darauf zurückzuführen, dass in diesem Modell etwa 300 unterschiedliche Schreiberhände trainiert wurden, die im Testset auch repräsentiert sein müssen. – In unserem Modell für die Assessorenvoten des Wismarer Tribunals sind etwa 46.000 Wörter im Trainingsset enthalten, das Testset umfasst lediglich 2.500 Wörter, also ein Anteil von etwa 5%. Wir haben es hier allerdings auch nur mit 5 verschiedenen Schreiberhänden zu tun. Für die Repräsentativität des Testsets genügt das Material also.