Language Models
Release 1.10.1
Wir haben in einem früheren Beitrag über die Verwendung von Wörterbüchern gesprochen und dabei erwähnt, dass – je besser ein HTR-Modell ist (CER besser als 7%) – der Nutzen eines Wörterbuches für das HTR-Ergebnis geringer wird.
Anders ist das beim Einsatz von Language Models, die seit Dezember 2019 in Transkribus verfügbar sind. Wie Wörterbücher werden auch Language Models bei jedem HTR-Training aus dem dort genutzten Ground Truth generiert. Anders als Wörterbücher zielen Language Models aber nicht auf die Identifizierung einzelner Wörter. Sie ermitteln stattdessen die Wahrscheinlichkeit für eine Wortfolge oder die regelmäßige Kombination von Wörtern und Ausdrücken in einem bestimmten Kontext.
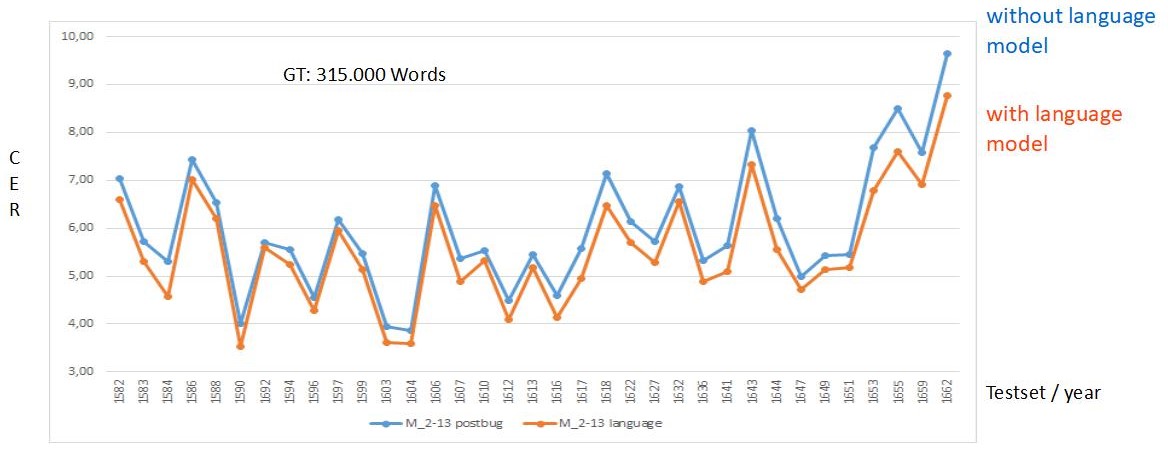
Anders als bei Wörterbüchern führt der Einsatz von Language Models immer zu wesentlich besseren HTR-Ergebnissen. In unseren Tests verbesserte sich die durchschnittliche CER im Vergleich zum HTR-Ergebnis ohne Language Model bis zu 1 % – und zwar durchweg, auf allen Testsets.
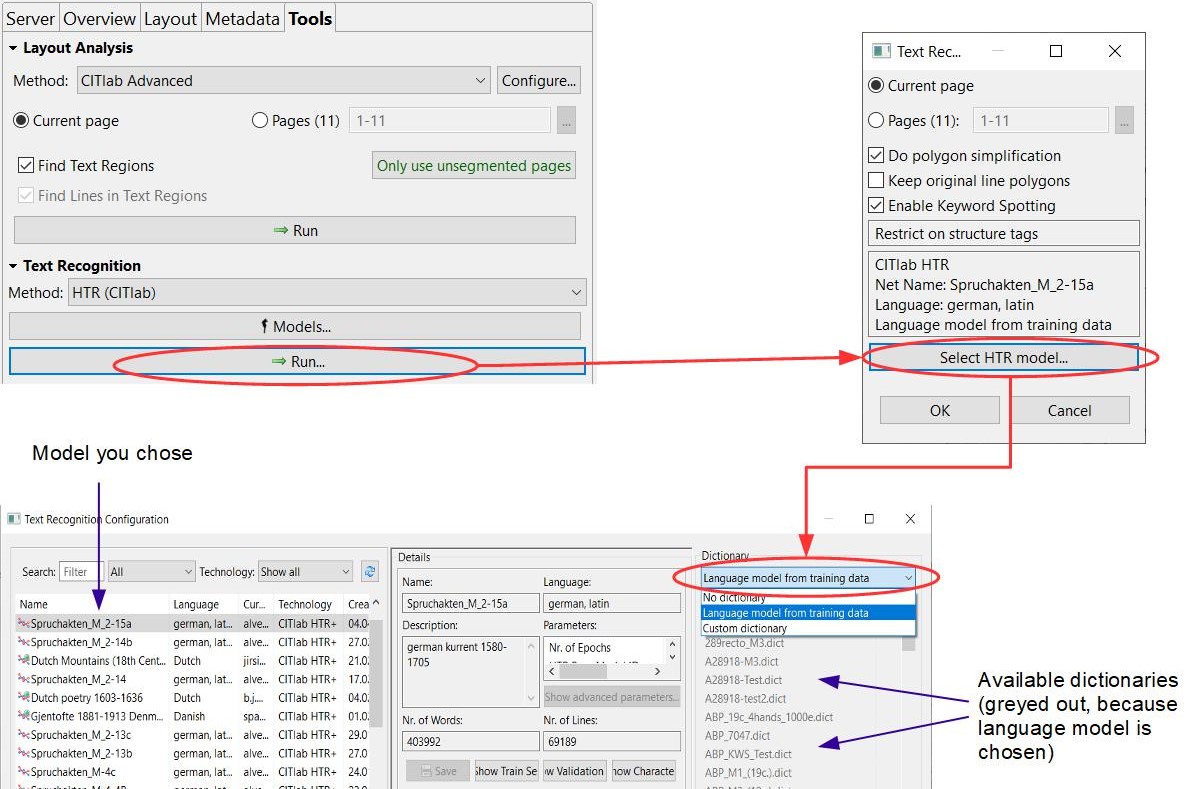
Tipps & Tools: Das Language Model kann bei der Konfiguration der HTR ausgewählt werden. Anders als bei Wörterbüchern sind Language Models und HTR-Modell nicht frei kombinierbar. Es wird immer das zum HTR-Modell generierte Language Model genutzt.