
Compare Samples
Release 1.10.1
Das Tool „Compare Samples“ überprüft, wie der Name schon sagt, die Fähigkeiten eines HTR-Modells nicht anhand eines manuell ausgewählten Testsets, sondern auf der Grundlage eines Samples. Wie man solche Samples erstellt, dass sie eine objektive Alternative zu konventionellen Testsets darstellen und warum sie mit wesentlich weniger Aufwand als diese erstellt werden können, haben wir in einem früheren Beitrag erklärt.
„Compare Samples“ sieht zwar aus wie ein Validierungs-Tool, gehört aber eigentlich nicht dazu. Nicht dass man damit ein HTR-Modell nicht validieren könnte, aber dafür ist das Advanced Compare eigentlich besser geeignet. Die eigentliche Funktion von „Sample Compare“ ist, dass es Voraussagen oder Prognosen über den Erfolg eines HTR-Modells auf einem bestimmten Material erstellt.
Ihr erinnert euch vielleicht an den Model Booster. Wenn man für ein geplantes HTR-Training unter den inzwischen zahlreichen verfügbaren Public Models ein geeignetes HTR-Modell sucht, das als Base Model dienen kann, dann bietet es sich an, das zuerst mit „Compare Samples“ auf seine Eignung zu überprüfen.
Um für ein Sample eine solche Voraussage zu erstellen, müsst ihr zuerst die ausgewählten HTR-Modelle über das gesamte Sample laufen lassen (Davor habt ihr natürlich für das Sample schon den GT erstellt). Anschließend öffnet ihr im „Compare Samples“-Tool den Reiter Samples. Darin sind sämtliche Samples deiner aktiven Collection aufgelistet. Ihr wählt das Sample aus, das als Grundlage für die Vorhersage dienen soll. Jetzt könnt ihr in der Mitte das Modell auswählen, dessen Textversion als Referenz für den GT dienen soll. „Compute“ starten und fertig.
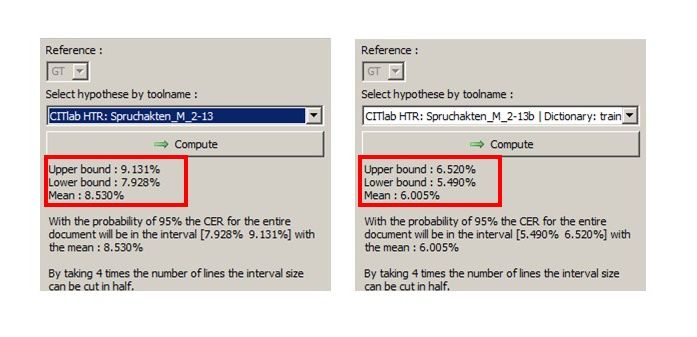
Das Tool errechnet euch jetzt Durchschnittswerte für alle Zeilen des Samples mit jeweils einem oberen Durchschnittswert (upper bound), einem unteren (lower bound) und einem Mittelwert. In der Spanne zwischen upper bound und lower bound sollte dann für 95 % eures Materials die Character Error Rate liegen mit der das gewählte HTR-Modell voraussichtlich arbeitet. In unserem Beispiel unten also zwischen 4,7 und 2,9 %.

Ihr könnt auf diese Art beliebig viele Modelle für euer Material vergleichen. Aber das Tool erlaubt auch ein paar andere Dinge. Ihr könnt z.B. sehr gut überprüfen, wie ein HTR-Modell mit oder ohne language model oder dictionary auf eurem Material arbeitet und ob sich also der Einsatz des einen oder anderen lohnt. Das bietet sich natürlich vor allem für die Überprüfung der eigenen Modelle an.
Tipps & Tools
Erstellt lieber mehrere kleinere Samples als ein gigantisches Sample für all euer Material. Ihr könnt sie z. B. chronologisch oder nach Schreiberhänden trennen. Das erlaubt euch später eine differenzierte Voraussage für den Einsatz von HTR-Modellen auf eurem gesamten Material oder auf Teilen davon.
