Auf den Schultern von Giganten: Training mit Basismodellen
Release 1.10.1
Wer generische HTR-Modelle entwickeln möchte, der kommt an der Arbeit mit Base Models nicht vorbei. Beim Training mit Base Models wird jeder Trainingsdurchgang für ein Modell auf der Grundlage eines bereits existierenden Modells, eben eines Base Models, durchgeführt. Das ist in der Regel das letzte HTR-Modell, das man in dem entsprechenden Projekt trainiert hat.
Base Models „erinnern“ sich an das, was sie bereits „gelernt“ haben. Daher verbessert auch jeder neue Trainingsdurchgang die Qualität des Modells (theoretisch). Das neue Modell lernt also von seinem Vorgänger und wird dadurch immer besser. Daher ist das Training mit Base Models auch für große generische Modelle, die über lange Zeit kontinuierlich weiterentwickelt werden, besonders geeignet.
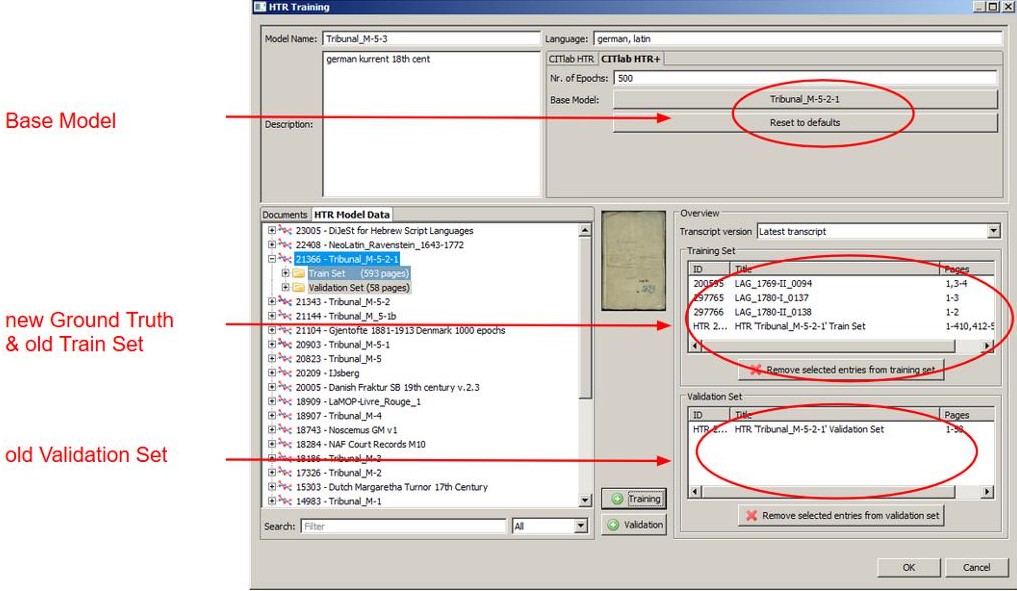
Um ein Training mit Base Model durchzuführen, wählt man im Trainingstool – neben den üblichen Einstellungen – einfach ein bestimmtes Base Model aus. Danach fügt man aus dem Reiter HTR Model Data das Train Set und und das Validation Set (in früheren Transkribus-Versionen als Test Set bezeichnet) des Base Models ein, sowie das neue Trainings und Validation Set. Zusätzlich kann man dann noch weiteren neuen Ground Truth hinzufügen und anschließend das Training starten.