Testsamples – die unparteiische Alternative
Wenn eine Projektkonzeption es nicht zulässt, den Aufbau von Testsets strategisch zu planen und zu organisieren, dann gibt es eine einfache Alternative: automatisch erstellte Samples. Sie stellen auch eine gute Ergänzung zu den von uns manuell erstellten Testsets dar, denn hier entscheiden nicht wir, sondern die Maschine, welches Material in das Testset kommt und welches nicht. Das läuft darauf hinaus, dass Transkribus einzelne Zeilen aus einer Menge von Seiten auswählt, die ihr natürlich zuvor zur Verfügung gestellt habt. Es handelt sich also um eine mehr oder weniger zufällige Auswahl. Das lohnt sich bei Projekten, die über sehr viel Material verfügen – also auch bei unserem.
Wir verwenden Samples als Gegenprobe zu unseren planmäßig manuell erstellten Testsets und weil Samples den statistischen Verfahren der Stichprobenerhebung vergleichbar sind, die die DFG in ihren Praxisregeln auch für die Überprüfung der Qualität der OCR empfiehlt.
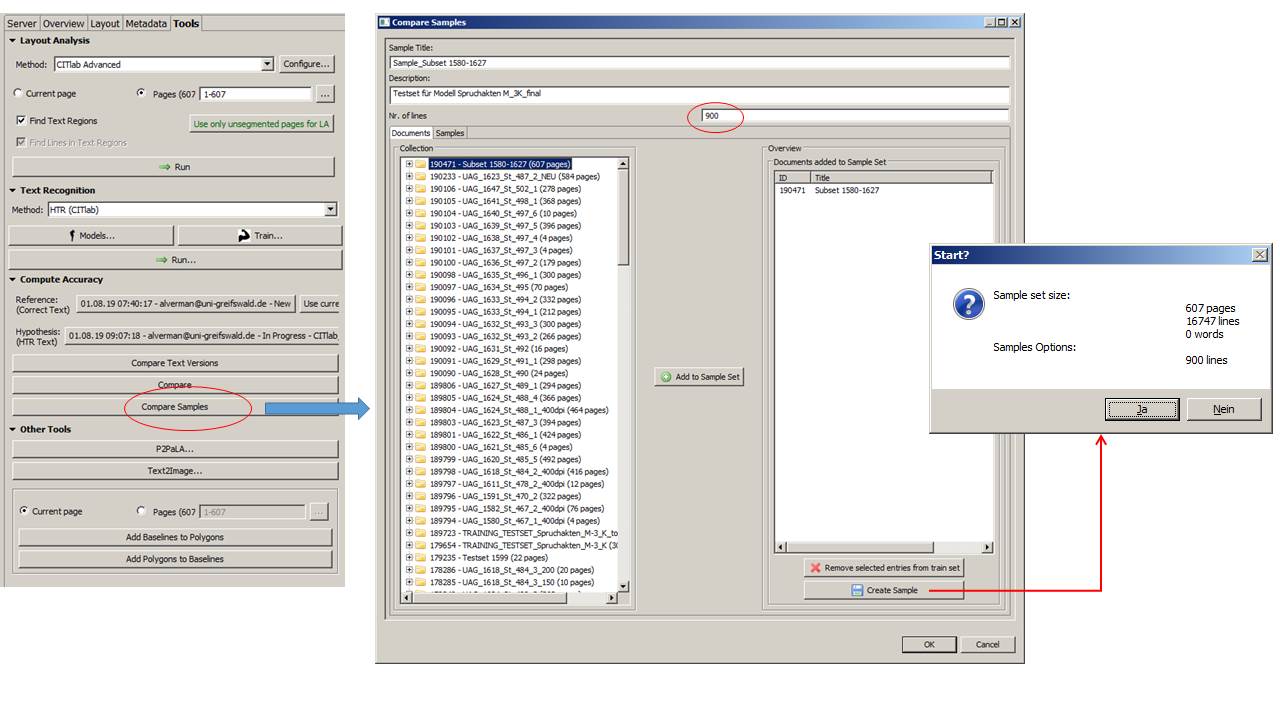
Da HTR (anders als OCR) zeilenbasiert arbeitet, wandeln wir die Empfehlung der DFG etwas ab. Ich erkläre das am konkreten Beispiel: Für unser Modell Spruchakten_M-3K sollte eine Überprüfung der erzielten Lesegenauigkeit vorgenommen werden. Für unser Sample wurde zunächst eine Stichprobe von 600 Seiten gezogen, verteilt über den Gesamtzeitraum, für den das Modell arbeitet (1583-1627) und ausschließlich aus untrainiertem Material. Dafür wurde jede 20. Seite des Datensets ausgewählt. Bezogen auf das gesamte für diesen Zeitraum zur Verfügung stehende Material von 16.500 Seiten repräsentiert dieses Subset ca. 3,7%. All das geschieht auf dem eigenen Netzlaufwerk. Nachdem dieses Subset in Transkribus hochgeladen und mit der CITlab Advanced LA verarbeitet wurde (16.747 lines wurden insgesamt erkannt), ließen wir Transkribus ein Sample daraus erstellen. Es enthält 900 per Zufallsgenerator ausgewählte Zeilen. Das sind also ca. 5% des Subsets. Dieses Sample wurde nun mit GT versehen und als Testset zur Überprüfung des Modells genutzt.
Und so geht das in der Praxis: Im Menü „Tools“ wird die Funktion „Sample Compare“ aufgerufen. Unser Subset wird in der Collection ausgewählt und mit dem Button „add to sample“ zum Sample Set hinzugefügt. Dabei geben wir auch die Anzahl der Zeilen an, die Transkribus aus dem Subset auswählen soll an. Wir wählen hier mindestens so viele Zeilen, wie Seiten im Subset vorhanden sind, so dass rechnerisch auf jede Seite eine Testzeile kommt. In unserem Fall haben wir uns für den Faktor 1,5 entschieden, um sicher zu gehen. Das Programm wählt die Zeilen nun eigenständig aus und stellt daraus ein Sample zusammen, das als neues Dokument gespeichert wird. Dieses Dokument enthält keine pages, sondern ausschließlich Zeilen. Die müssen nun – wie gewohnt – transkribiert und so GT erzeugt werden. Anschließend kann jedes beliebige Modell über die Compare-Funktion an diesem Testset ausprobiert werden.