Anwendungsfall: Erweiterung und Verbesserung bestehender HTR-Modelle
Release 1.10.1
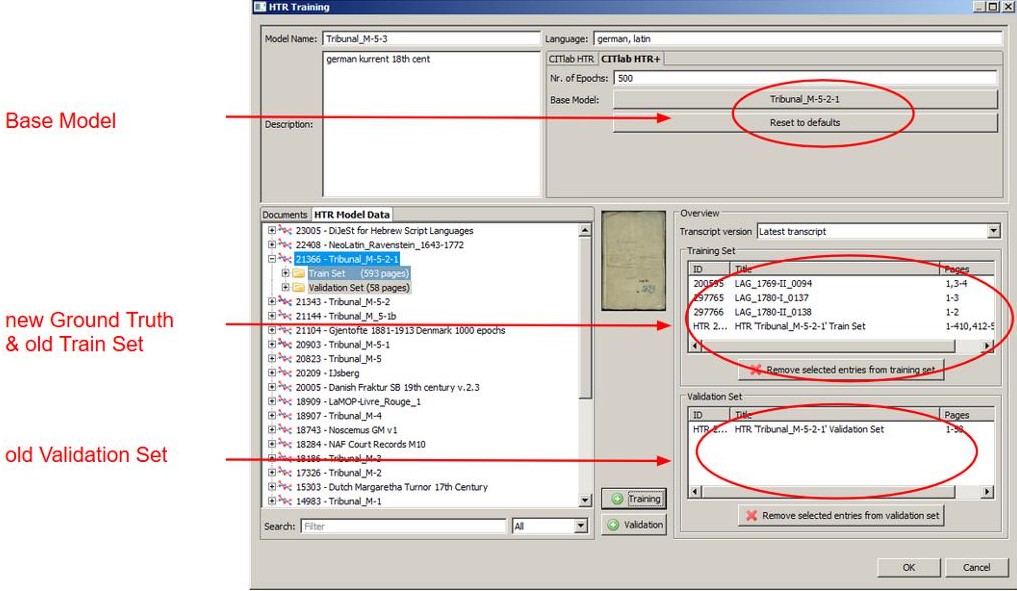
Im letzten Beitrag haben wir beschrieben, dass ein Base Model alles was es bereits “gelernt” hat, an das neue HTR-Modell weitergeben kann. Mit zusätzlichem Ground Truth kann das neue Modell dann seine Fähigkeiten erweitern und verbessern.
Hier nun ein typischer Anwendungsfall: In unserem Teilprojekt zu den Assessorenvoten des Wismarer Tribunals trainieren wir ein Modell mit acht verschiednene Schreibern. Das Train Set umfasst 150.000 Wörter, die CER lag beim letzten Training bei 4,09 %. Allerdings war die durchschnittliche CER für einzelne Schreiber viel höher als für andere.
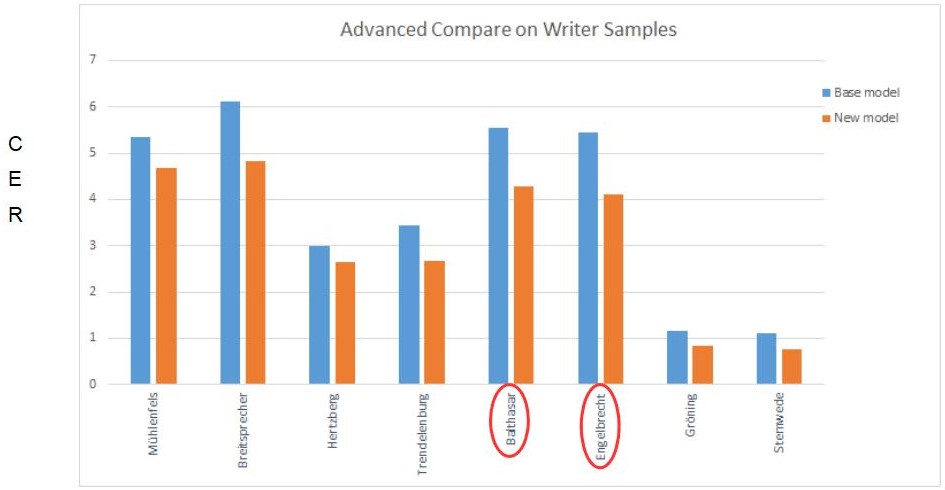
Wir entschieden uns also für ein Experiment. Wir fügten 10.000 Wörter neuen GT für zwei der auffälligen Schreiber (Balthasar und Engelbrecht) hinzu und nutzten das Base Model und dessen Trainings- und Validation Set für das neue Training.
Das neue Modell hatte im Ergebnis eine durchschnittliche CER von 3,82 % – es hatte sich also verbessert. Was aber bemerkenswert ist, ist das nicht nur die CER für die beiden Schreiber verbessert wurde, für die wir neuen GT hinzugefügt hatten – in beiden Fällen um bis zu 1%. Auch die Zuverlässigkeit des Modells für die anderen Schreiber hat nicht gelitten, sondern sich im Gegenteil, ebenfalls verbessert.