
Textregionen
Release 1.7.1
Im Normalfall wird die automatische CITlab Advanced Layout Analysis in ihrer Standardeinstellung auf einem image nur eine einzige Textregion mit den dazugehörigen Baselines erkennen.
Es gibt aber auch einfache Layouts, bei denen sich der Einsatz mehrere TRs empfiehlt, bspw. wenn Marginalien, Rand- oder Fußnotizen und ähnliche wiederkehrende Elemente vorhanden sind. Solange diese inhaltlich und strukturell unterschiedlichen Textbereiche in einer einzigen TR enthalten sind, zählt die Layoutanalyse die Zeilen schlicht der Reihenfolge nach von oben nach unten.

Diese „Reading Order“ nimmt keine Rücksicht darauf, wo ein Text inhaltlich eigentlich hingehört (bspw. eine Einfügung), sondern nur darauf wo er grafisch auf der Seite verortet ist. Eine automatisch erzeugte, aber unbefriedigende Reading Order zu korrigieren ist langweilig und manchmal aufwendig. Man kann das Problem oft vermeiden, indem man mehrere Textregions anlegt in denen die zusammengehörigen Texte und Zeilen wie in einer Box gut aufgehoben sind.
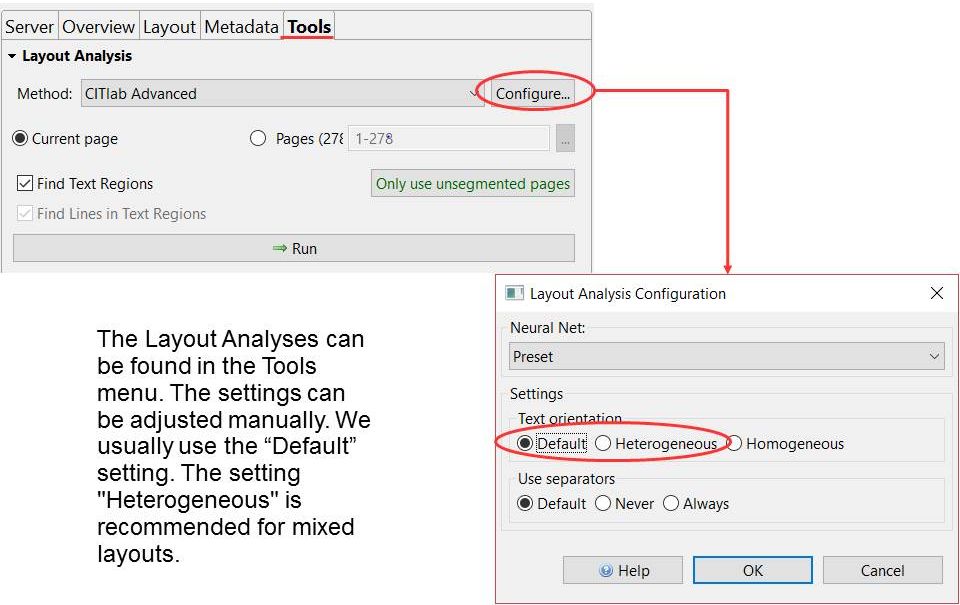
Dazu werden an den entsprechenden Stellen TRs manuell angelegt. Anschließend führt man die Line Detection mit CITlab Advanced durch um die Baselines automatisch hinzuzufügen.
Tipps & Tools
Wenn ihr die TRs manuell gezogen habt und nun von der CITlab Advanced LA die Baselines gezogen haben wollt, solltet ihr zuerst den Haken bei „Find Textregions“ herausnehmen, sonst werden die manuell gezogenen TRs gleich wieder überschrieben. Außerdem sollte man dafür sorgen, dass keine der einzelnen Textregionen aktiv ist, sonst wird nur diese bearbeitet.
